C++ 的 string 为什么不提供 split 函数?
string split 是一个既简单又复杂的东西。
说它简单,是因为实现一个string split本身代码量很少,逻辑不复杂,这个问题甚至常见于编程教材的课后习题,很适合用来给编程的初学者拿来练手,一般几行或者十几行代码就能搞定。
说它复杂,是因为需求很不统一,很难“标准化”。比如举几个例子:
1、字符串"aa,bb,cc",用","来分割,答案很明确,结果为三段,分别为"aa","bb"和"cc"。
2、字符串",aa,,bb,",还是用","来分割,结果应该是什么呢?有时候我们需要它的结构是分为两段即"aa"和"bb",但有时候我们希望它的结果是五段,即"\0","aa","\0","\0","bb"和"\0",你看不同的需求就出来了。
3、字符串"abababa",用"ab"来分割,你希望结果是什么呢?用"aba"来分割呢?
4、更极端的例子,字符串"abababa",同时用"a","b","ab","ba"来分割,结果应该是什么呢?
5、空字符串"\0"被分割,结果应该如何?
也许你觉得这些都是corner case,业务中遇不到,但是如果你要写成一个通用的库,这些corner case就不得不考虑。那就会出现矛盾,如果覆盖所有的corner case,那无疑就会“过度设计”,而如果不“过度设计”就很难“通用”。
比如谷歌的abseil库,设计了AllowEmpty,SkipEmpty和SkipWhitespace等分割模式,boost也有类似的设计,可是即使这样,也不能覆盖所有的场景。
既然需求多样难以满足,同时又逻辑简单谁都会写,那不如交给程序员自己去写好了。
我是很鼓励程序员造轮子的,几行代码满足自己的需求,同时达到更快的速度,有什么不好呢?
这里吐槽一下一些大厂第三方库的string split,它们真的没有好好写。这么一个简单而常用的轮子,按说谁写运行速度都不会相差多大,没有多少优化的空间,可实际情况是,它们为啥把string split搞得这么慢?一个测试:
#include "morn_util.h"
#include <string>
#include <vector>
#include <boost/algorithm/string.hpp>
#include <boost/algorithm/string_regex.hpp>
#include <absl/strings/str_split.h>
#include <folly/String.h>
void test1()
{
printf("\nsplit with \"\\n\":\n");
MString *text=mStringCreate();
mText(text,"../data/a_Q_zheng_zhuan.txt");
std::string str(text->string);
std::vector<std::string> vec1;
mTimerBegin("boost");
for(int i=0;i<1000;i++)
boost::split(vec1,str,boost::is_any_of("\n"),boost::token_compress_off);
mTimerEnd("boost");
printf("vec.size()=%ld\n",vec1.size());
std::vector<std::string> vec2;
mTimerBegin("absl");
for(int i=0;i<1000;i++)
vec2=absl::StrSplit(str,'\n');
mTimerEnd("absl");
printf("vec.size()=%ld\n",vec2.size());
std::vector<std::string> vec3;
mTimerBegin("folly");
for(int i=0;i<1000;i++)
{
vec3.clear();
folly::split('\n',str,vec3);
}
mTimerEnd("folly");
printf("vec.size()=%ld\n",vec3.size());
MList *list;
mTimerBegin("Morn");
for(int i=0;i<1000;i++)
list=mStringSplit(text,"\n");
mTimerEnd("Morn");
printf("list->num=%d\n",list->num);
mStringRelease(text);
}
void test2()
{
printf("\nsplit with \"。\":\n");
MString *text=mStringCreate();
mText(text,"../data/a_Q_zheng_zhuan.txt");
std::string str(text->string);
std::vector<std::string> vec1;
mTimerBegin("boost");
for(int i=0;i<1000;i++)
boost::algorithm::split_regex(vec1,str,boost::regex("。"));
mTimerEnd("boost");
printf("vec.size()=%ld\n",vec1.size());
std::vector<std::string> vec2;
mTimerBegin("absl");
for(int i=0;i<1000;i++)
vec2=absl::StrSplit(str,"。");
mTimerEnd("absl");
printf("vec.size()=%ld\n",vec2.size());
std::vector<std::string> vec3;
mTimerBegin("folly");
for(int i=0;i<1000;i++)
{
vec3.clear();
folly::split("。",str,vec3);
}
mTimerEnd("folly");
printf("vec.size()=%ld\n",vec3.size());
MList *list;
mTimerBegin("Morn");
for(int i=0;i<1000;i++)
list=mStringSplit(text,"。");
mTimerEnd("Morn");
printf("list->num=%d\n",list->num);
mStringRelease(text);
}
int main()
{
test1();
test2();
return 0;
}
以上,使用鲁迅先生的中篇小说《阿Q正传》为例子进行测试,分别对字符串进行:1、段分割(单字符分割,分割符为换行符"\n"),2、句分割(字符串分割,分割符为汉语句号"。")。测试对象是三个很著名的库,boost,abseil和folly,以及自己写的C语言基础库Morn,分别测试1000次。测试结果为:
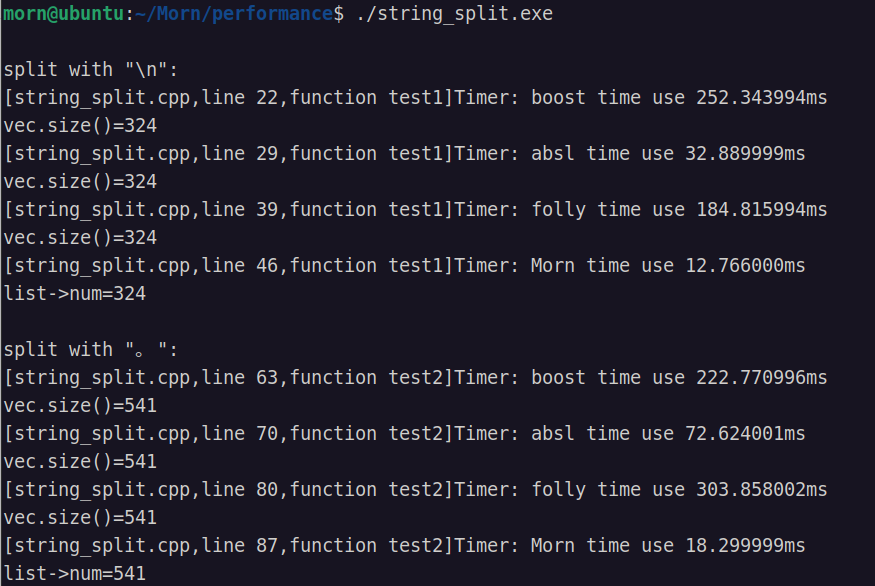
运算的结果是一样的,但自己写的程序比其他三个库快了几倍到几十倍。所以,string split这种简单的程序,完全不需要到处去找第三方库。